PSUG #103 (Part 1 )— Gestion systématique d’erreur avec ZIO
Vous n’avez pas pu assister au dernier PSUG ? Pas de panique !
Voici un récap’ de la présentation de François Armand (CTO & Founder chez Rudder) !
Rudder sur ZIO — Gestion systématique des erreurs dans vos applications — par Francois Armand. “Notre métier de développeur consiste essentiellement à anticiper et gérer les cas non nominaux d’une application”. Cet état d’esprit est central dans le développement de Rudder et c’est aussi la source d’un bon nombre de nos choix techniques, dont le dernier en date: ZIO
Developer ? Not so popular opinions
Our work as developers is to discover and assess failure modes.
ERRORS are a SOCIAL construction to give AGENCY to the receiver of the error.
An application always has at least 3 kinds of users : users, devs and ops. Don’t forget any.
It’s YOUR work to choose the SEMANTIC between nominal case and error and KEEP your PROMISES
OK. But in concret terms ?
Assess failure modes.
Give agency to your users and don’t forget any of them.
You are responsible to keep promises made.
Pure, total functions
Explicit error channel
Failures vs Errors
Program to strict interfaces and protocols
Composition and tooling
These points are also important and cans be translated at architecture / UX / team / ecosystem levels.
But let’s keep it simple with code.
1 — Don’t lie about your promises
Pure, total functions
Don’t lie to your users, allow them to react efficiently :
Use total functions // or make them total with union return type
Use pure functions // or make them pure with IO monad
2 — Make it unambiguous in your types
Explicit error channel
It’s a signal, make it unambiguous, give agency, automate it
Don’t assume what’s obvious
It’s an open world out there
Don’t force users to revert-engineer possible cases
Which intent is less ambiguous ?
Use the type system to automate classification of errors ?
“A type system is a tractable syntactic method for proving the absence of certain program behaviors by classifying phrases according to the kinds of values they compute.” — Benjamin Pierce
By definition, a type system automatically categorize results
⟹ need for a dedicated error chanel + a common error trait
Same for effectful functions !
Use a dedicated error channel :
~ Either[E, A] for pure code,
else ~ IO[E, A] monad
Use a parent trait for common error properties …
And for automatic categorization of error by compiler
3 — Models are false by construction
Failures vs Errors
Model everything ?
→ Where is the limit ?
Systems ?
Need for a systematic approach to error management
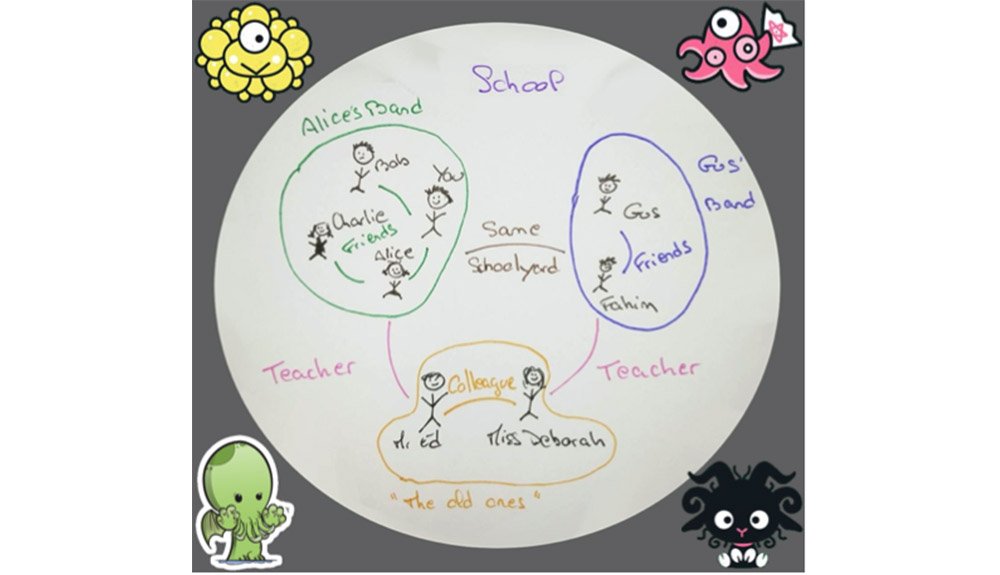
A school of systems
BOUNDED group of things, with a NAME, Interacting with other systems
Systems have horizon
Nothing exists beyond horizon
Systems have horizon. Horrors lie beyond.
Nothing exists beyond horizon.
Like with Lovecraft : if something from beyond interact with a system, the system becomes inconsistent.
Errors vs Failures :
Errors :
expected non nominal case
signal for users
social construction: you choose alternative or error
reflected in types
Failures :
unexpected case: by definition, application is in an unknown state
only choice is stop as cleanly as possible
not reflected in types
Horizon limit is your choice — by definition
⟹ SecurityException is an expected error case here
… but nowhere else in Rudder. By our choice.
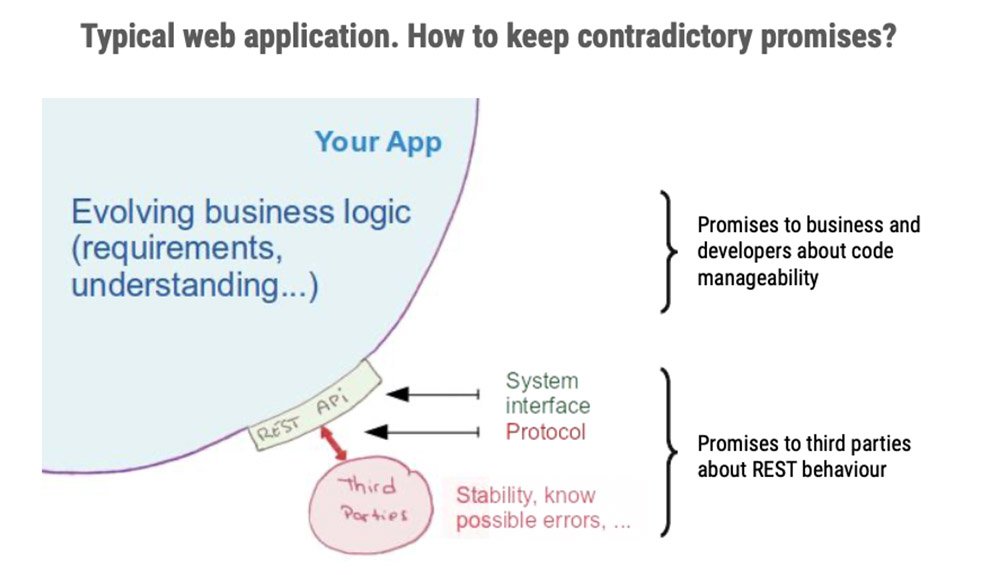
4 — Use systems to materialize promises
Program to strict interfaces and protocols
A bit more about systems
Need for a systematic approach to error management
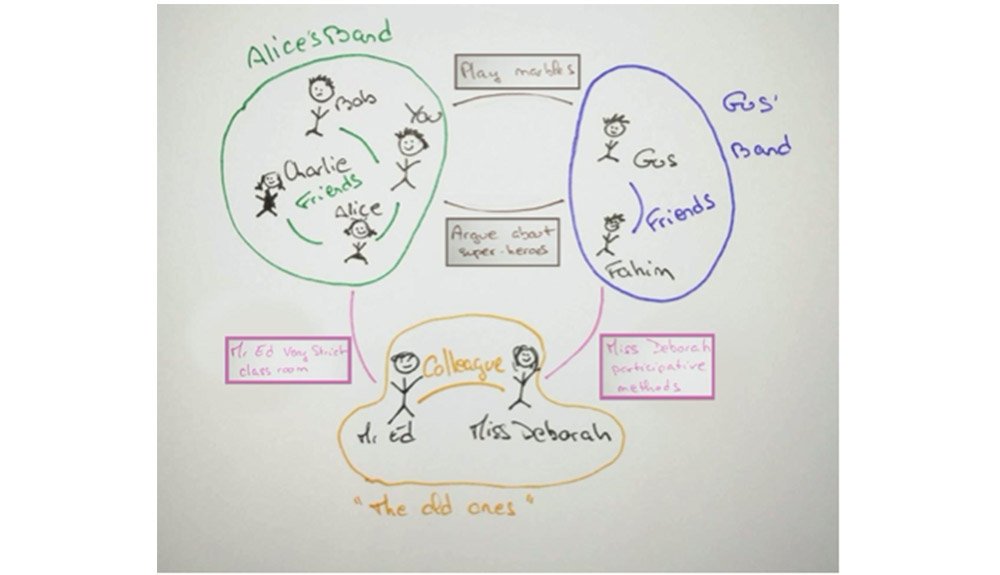
BOUNDED group of things with a NAME Interacting via INTERFACES by a PROTOCOL with other systems and PROMISING to have a behavior.
Example ?Make promises, keep them
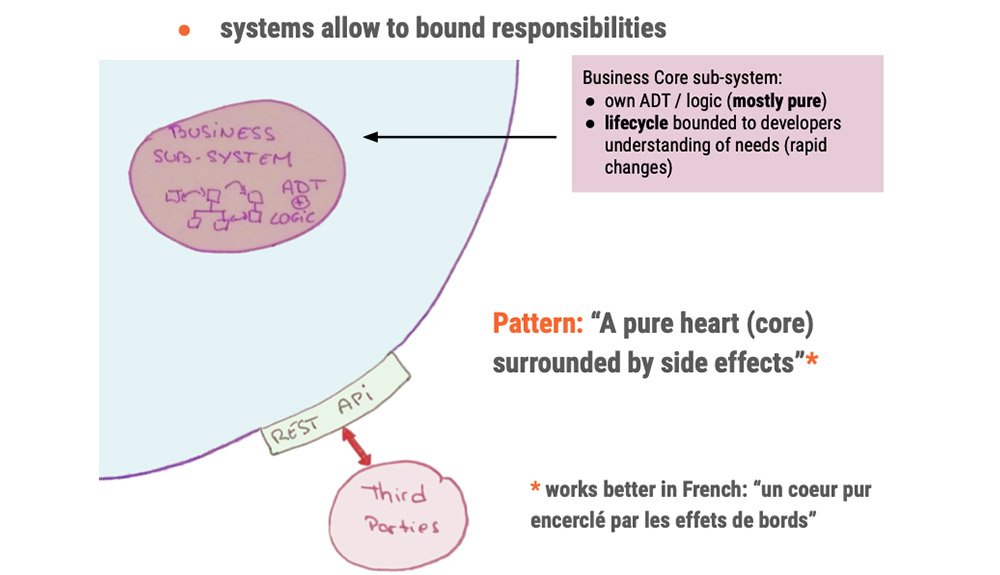
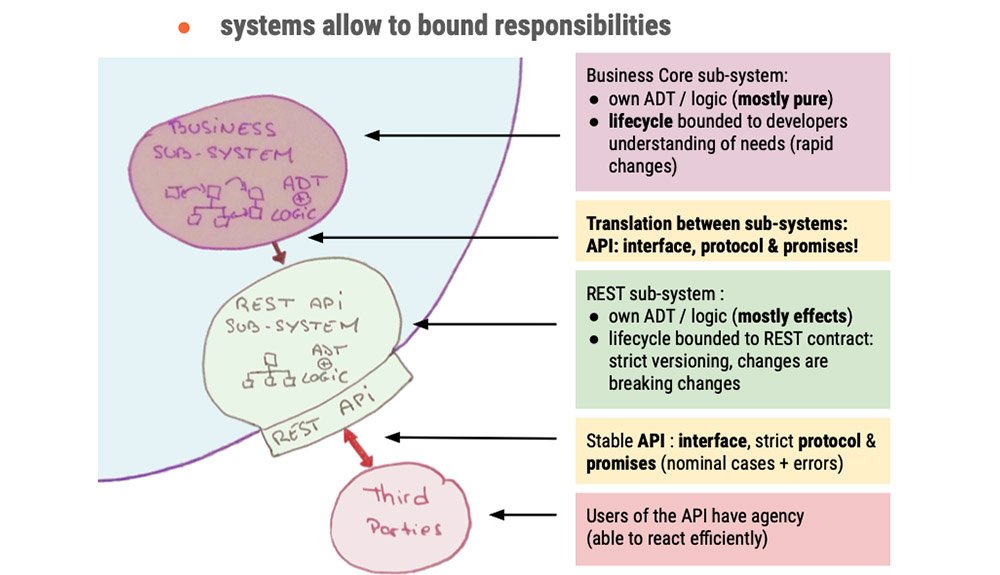
systems allow to bound responsibilities
translate errors between sub-systems
*make errors relevant to their users
It’s a model, it’s false
*there is NO definitive answer
*discuss, share, iterate
the bigger the promises, the stricter the API
5 — Make it extremely convenient tu use
Composition and tooling
Unpopular opinion : Checked exceptions are good signal for users. Who likes them ?
What’s missing for good error management in code ?
signal must be unambiguous
*exception are a pile of ambiguity
exceptions are A PAIN to use
*no tooling, no inference, nothing
→ you need to be able to manipulate errors like normal code
→ where are our higher order functions like map, fold, etc ?
*no composition
→ loose referential transparency*
the single biggest win regarding code comprehension
Make it joy !
managing error should be enjoyable !
*automatic (in for loop + inference)
*or as expressive as nominal case!
safely, easely managing error should be the default !
*add all the combinators you need!
*it’s cheap with pure, total functions
In Rudder : Why ZIO ?
You still have to think in systems by yourself, then ZIO provides :
Effect management
With an explicit error channel
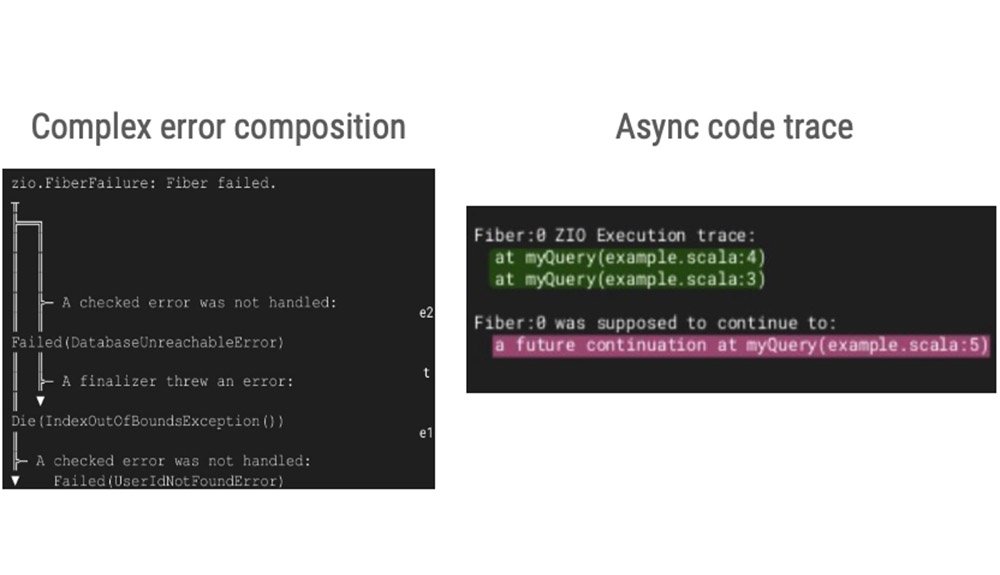
Debuggable failures
Tons of convenience to manipulate errors
→ create: from Option, Either, value…
→ transform: mapError, fold, foldM, ..
→ recovery: total, partial, or else
Composable effects
→ .bracket / Managed, asyncqueues, STM, etc : safe, composable resource management
Everything work in parallel, concurrent code too !Inference just work !Lots of details: “Error Management: Future vs ZIO”
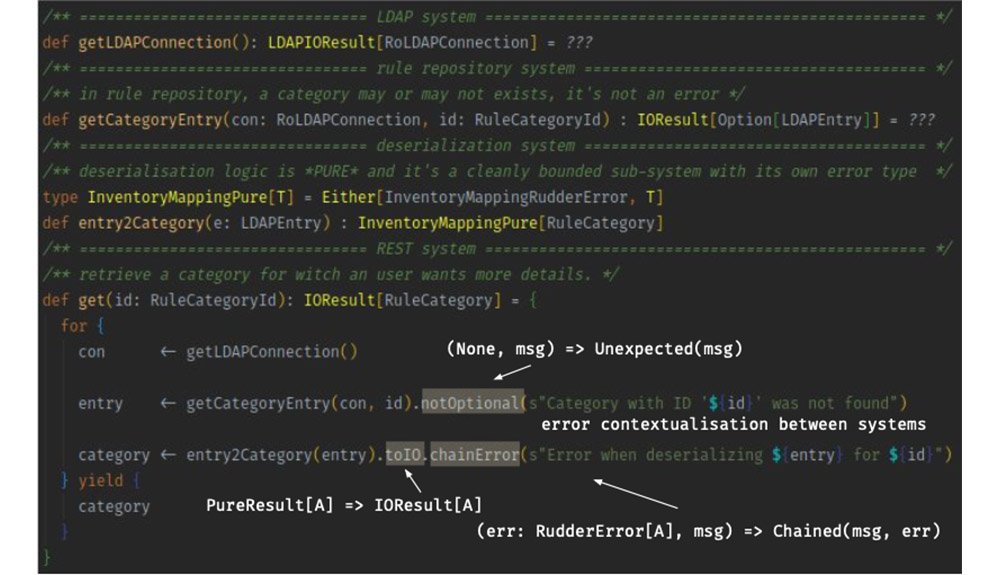
In Rudder, with ZIO : We settled on that
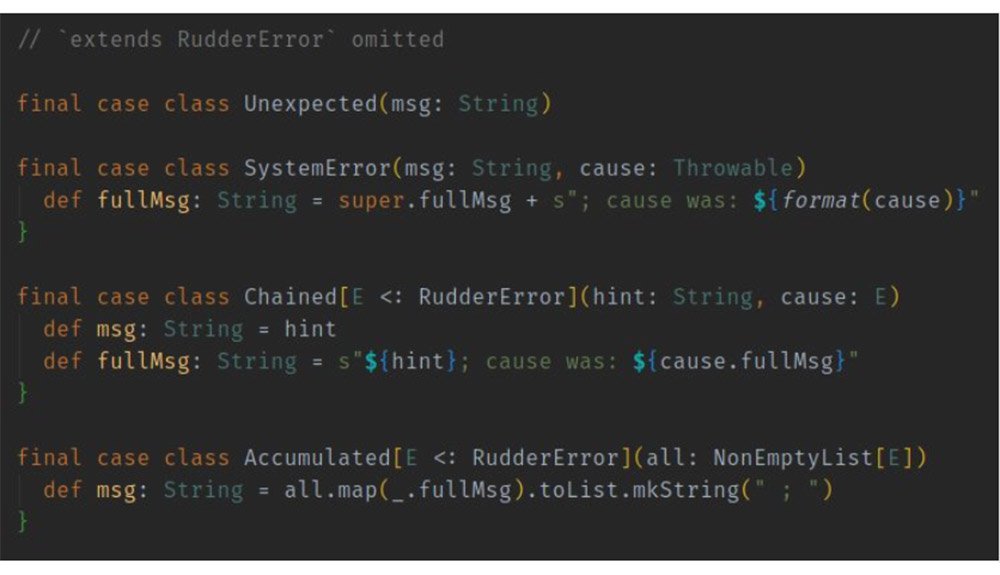
One Error hierarchy
One error type (trait) providing common tooling
Unambiguous typeGeneric useful errorsSpecialized error for subsystemsFull example :
Some questions asked after the talk :
What about making impossible state unrepresentable from the beginning?
→ That’s a very good point and you should ALWAYS try to do so. The idea is to change method’s domain definition (ie, the parameter’s shape) to only work on inputs that can’t rise errors. Typically, in my trivial “divide” example, we should have use “non zero integer” for denominator input.
→ Alexis King (@lexy_lambda) wrote a wonderful article on that, so just go read it, she explains it better than I can
“Parse, don’t validate” https://lexilambda.github.io/blog/2019/11/05/parse-don-t-validate/
→ We use that technique a lot in Rudder to drive understanding of what is possible. Each time we can restrict domain definition, we try to keep that information for latter use.
→ Typical example: parsing plugin license (we have 4 “xxxLicenses” classes depending what we now about its state); Validating user policy (again several “SomethingPolicyDraft” with different hypothesis needed to build the “Something”).
→ the general goal is the same than with error management: assess failure mode, give agency to users to react efficiently.
→ There’s still plenty of cases where that technique is hard to use (fluzzy business cases…) or not what you are looking for (you just want to tell users that something is the nominal case, or not, and give them agency to react accordingly).
Is SystemError used to catch / materialize failure ?
→ no, SystemError is here to translate Error that need to be dealts with (like connection error to DB, FS related problem, etc) but are encoded in Java with an Exception. SystemError is not used to catch Java “OutOfMemoryError”. These exception kills Rudder. We use the JVM Thread.setDefaultUncaughtExceptionHandler to try to give more information to dev/ops and clean things before killing the app.
You have only one parent type for errors. Don’t you lose a lot of details with all special errors in subsystems losing the specificities when they are seen as RudderError?
→ This is a very pertinent question, and we spend a log of time pondering between the current design and one where all sub-systems would have their own error type (with no common super type). In the end, we settled on the current design because:
1 — no common super type means no automatic inference. You need to guide it with transformer, and even if ZIO provide tooling to map errors, that means a lot of useless boilerplate that pollute the readability of your code.
2 — there is common tooling that you really want to have in all errors (Chained, SystemError, but also “notOptional”, etc). You don’t want to rewrite them. Yes type class could be a solution, but you still have to write them, for no clear gain here.
3 — you are fighting the automatic categorization done by the compiler in place of leveraging it.
4 — The gain (detailed error) is actually almost never needed. When we switched to “only one super class for all error”, we saw that “Chained” is sufficient to deals with general trans-system cases, and in some very, very rare cases, you case build ad-hoc combinators when needed, it’s cheap.
→ So all in all, the wins in convenience and joy of just having evering working without boilerplate clearly outpaced the not clear gain of having different error hierarchies.
→ The problem would have been different if Rudder was not one monolithic app with a need of separated compilation between services. I think we would have made an “error” lib in that case.
We use Future[Either[E,A]] + MTL, why should we switch to ZIO?
→ Well, the decision to switch is yours, and I don’t know the specific context of your company to give an advice on that. Nonetheless, here is my personal opinion:
1 — ZIO stack seems simpler (less concepts) and work perfectly with inference. Thus it may be simpler to teach it to new people, and to maintain. YMMV.
2 — ZIO perf are excellent, especially regarding concurrent code. Fibers are a very nice abstraction to work with.
3 — ZIO enforce pure code, which is generally simpler to compose/refactor.
4 — ZIO tooling and linked construction (Managed resources, Async Queues, STM, etc) are a joy to code with. It removes a lot of pains in tedious, boring, complicated tasks (closing resources correctly, sync between concurrent access, etc)
5 — pertinent stack trace in concurrent code is a major win
But at the end of the day, you decide!
How long did it took to port Rudder to ZIO?
→ It’s complicated :). 1 month of part time (me), plus lots more time for teaching, refactoring, understanding new paradigm limits, etc
1 — we didn’t started from nowhere. We were using Box from liftweb, and a lot of the code in Rudder was already “shaped” to deal with errors as explain in the talk (see https://issues.rudder.io/issues/14870 for context)
2 — we didn’t ported all Rudder to ZIO. I estimated that we ported ~ 40% of the code (60k-70k lines ?).
3 — we did some major refactoring along the lines, using new combinators and higher level structures (like async queues)
4 — we started in end of 2018, when ZIO code was still moving a lot and we switch to new things we when became available (ZIO 1.0.0 is around the corner and it as been quite stable for months now)
5 — we spent quite some time looking for the best choice for errors between sub-system (see other question)
Pour lire la 2nd partie du meetup, par François Laroche (Lead Developer Scala chez Make.org), c’est par ici !
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations sur l'appareil. Le consentement à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les identifiants uniques sur ce site. Ne pas consentir ou retirer son consentement peut affecter négativement certaines caractéristiques et fonctions.
Fonctionnel
Always active
Le stockage ou l'accès technique est strictement nécessaire dans le but légitime de permettre l'utilisation d'un service spécifique explicitement demandé par l'abonné ou l'utilisateur, ou dans le seul but d'effectuer la transmission d'une communication sur un réseau de communications électroniques.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistiques
The technical storage or access that is used exclusively for statistical purposes.Le stockage ou l'accès technique qui est utilisé exclusivement à des fins statistiques anonymes. Sans assignation à comparaître, conformité volontaire de la part de votre fournisseur de services Internet ou enregistrements supplémentaires d'un tiers, les informations stockées ou récupérées à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l'accès technique est nécessaire pour créer des profils d'utilisateurs pour envoyer de la publicité ou pour suivre l'utilisateur sur un site Web ou sur plusieurs sites Web à des fins de marketing similaires.


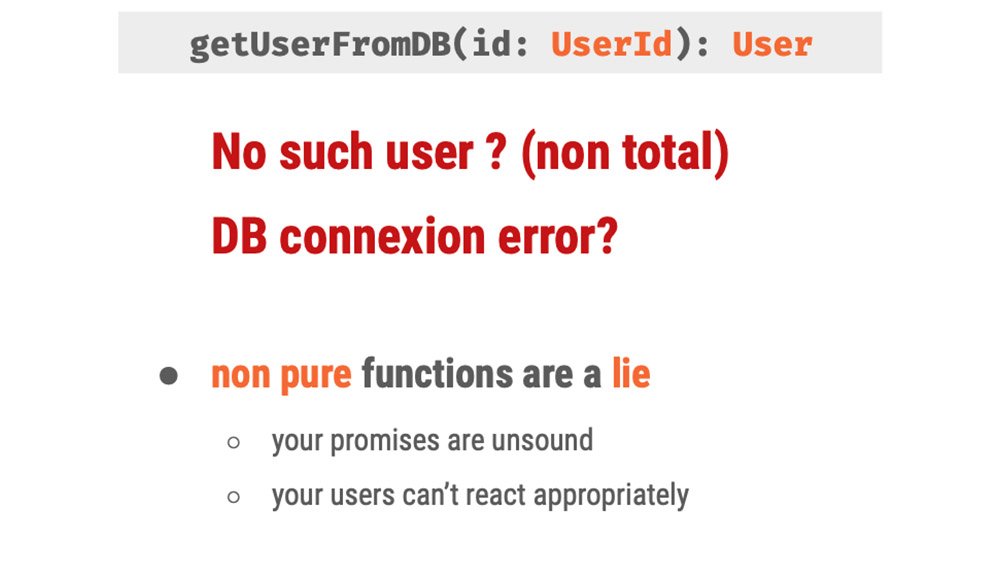 Don’t lie to your users, allow them to react efficiently :
Don’t lie to your users, allow them to react efficiently :
 Use the type system to automate classification of errors ?
“A type system is a tractable syntactic method for proving the absence of certain program behaviors by classifying phrases according to the kinds of values they compute.” — Benjamin Pierce
By definition, a type system automatically categorize results
⟹ need for a dedicated error chanel + a common error trait
Use the type system to automate classification of errors ?
“A type system is a tractable syntactic method for proving the absence of certain program behaviors by classifying phrases according to the kinds of values they compute.” — Benjamin Pierce
By definition, a type system automatically categorize results
⟹ need for a dedicated error chanel + a common error trait
 Same for effectful functions !
Same for effectful functions !
 Use a dedicated error channel :
~ Either[E, A] for pure code,
else ~ IO[E, A] monad
Use a dedicated error channel :
~ Either[E, A] for pure code,
else ~ IO[E, A] monad
 → Where is the limit ?
Systems ?
Need for a systematic approach to error management
→ Where is the limit ?
Systems ?
Need for a systematic approach to error management
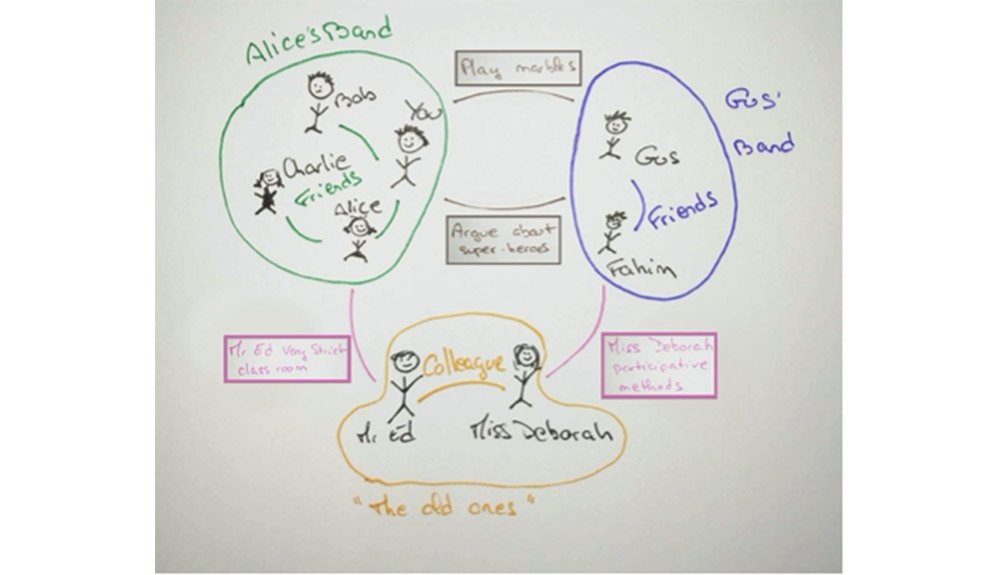 A school of systems
BOUNDED group of things, with a NAME, Interacting with other systems
Systems have horizon
A school of systems
BOUNDED group of things, with a NAME, Interacting with other systems
Systems have horizon
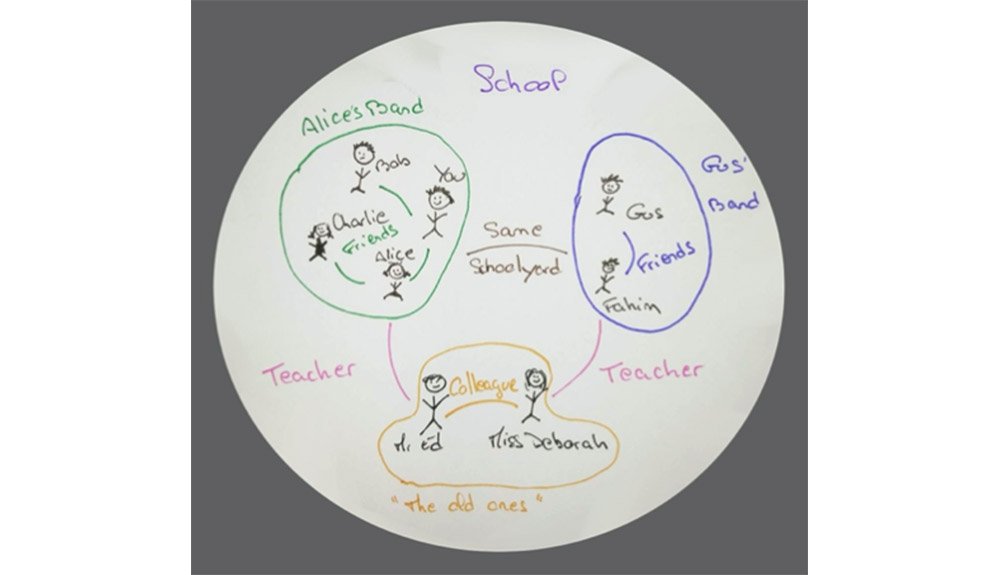 Nothing exists beyond horizon
Systems have horizon. Horrors lie beyond.
Nothing exists beyond horizon
Systems have horizon. Horrors lie beyond.
 ⟹ SecurityException is an expected error case here
… but nowhere else in Rudder. By our choice.
⟹ SecurityException is an expected error case here
… but nowhere else in Rudder. By our choice.
 BOUNDED group of things with a NAME Interacting via INTERFACES by a PROTOCOL with other systems and PROMISING to have a behavior.
Example ?
BOUNDED group of things with a NAME Interacting via INTERFACES by a PROTOCOL with other systems and PROMISING to have a behavior.
Example ?
 Make promises, keep them
Make promises, keep them

{kind=link}
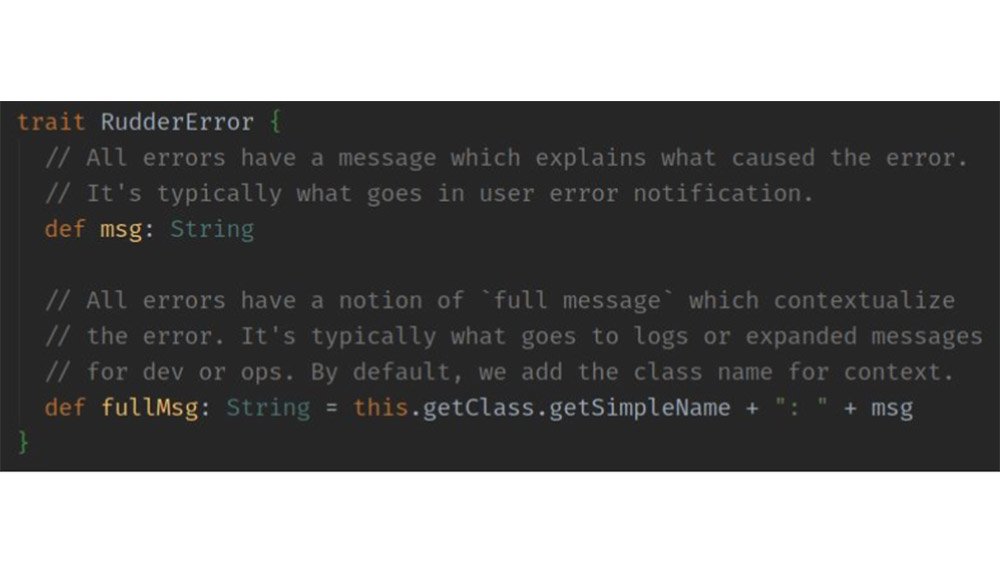 Unambiguous type
Unambiguous type
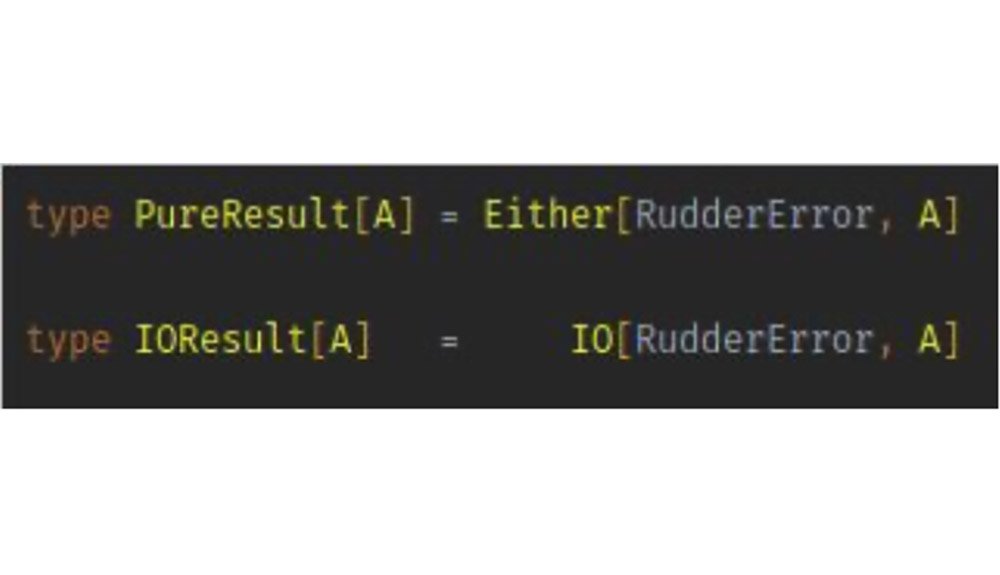 Generic useful errors
Generic useful errors
 Specialized error for subsystems
Specialized error for subsystems
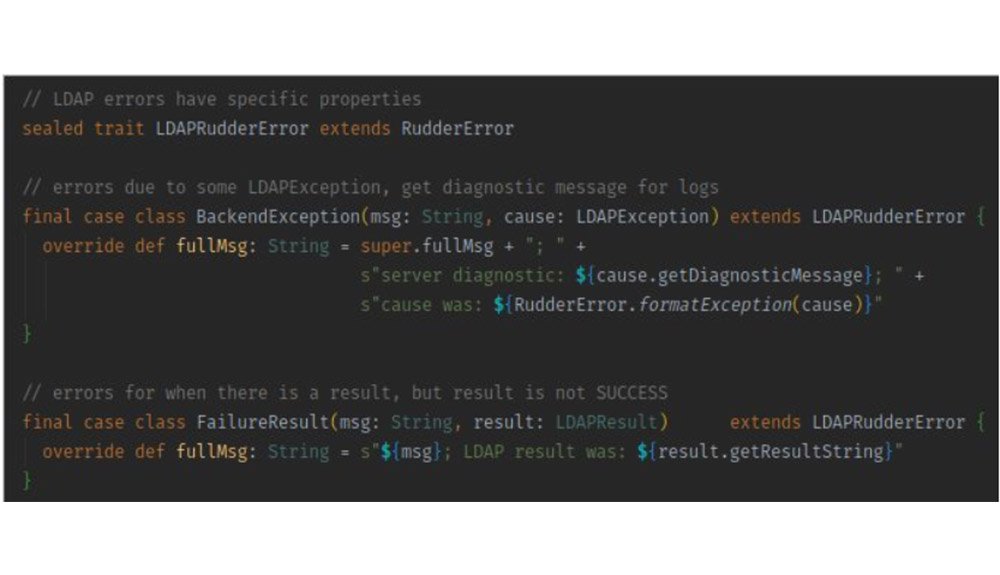 Full example :
Full example :