
Vous n’avez pas pu assister au dernier PSUG ? Pas de panique !
Voici un récap’ de la présentation de François Laroche (Lead Developer Scala chez Make.org) !
Retour d’expérience sur l’utilisation d’Akka en production, pièges et récompenses.
“Celà fait maintenant deux ans que nous avons mis en production notre application akka. Nous avons choisi Akka pour : — Pics de charge pouvant être assez élevés — Haute disponibilité — Architecture basée sur les données — Aisance de développement Akka a-t-il tenu ses promesses ?”
Make.org
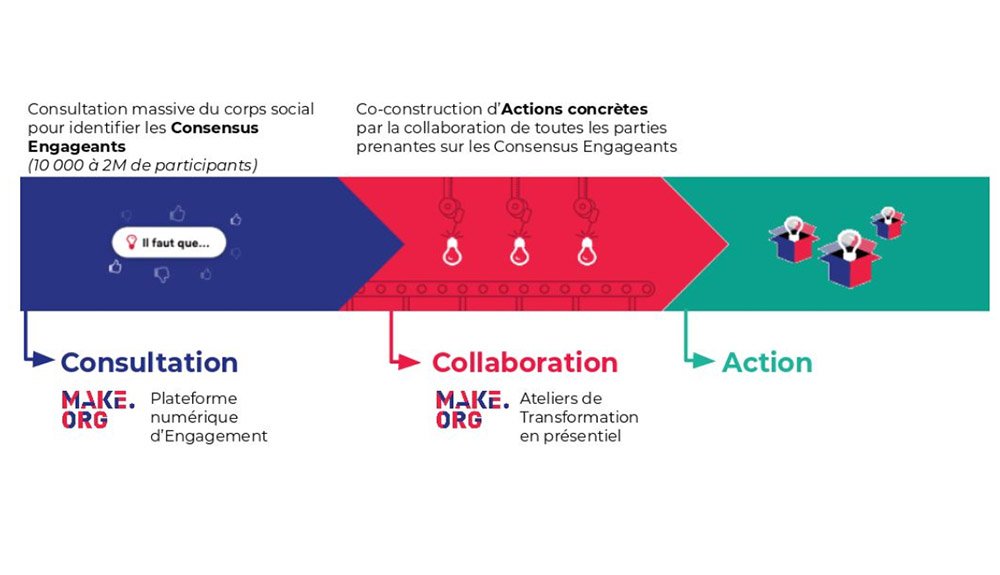
Les consultations de Make.org
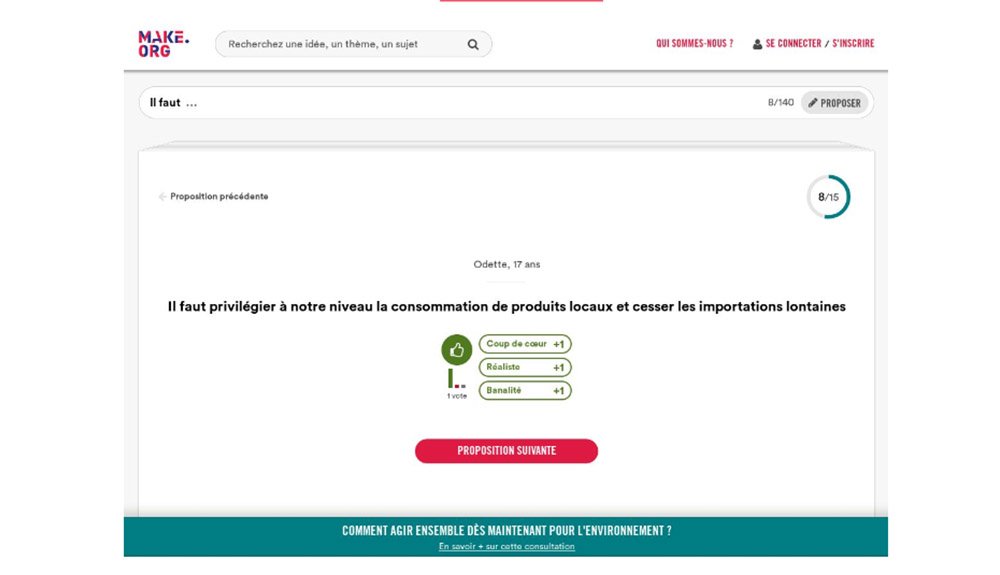
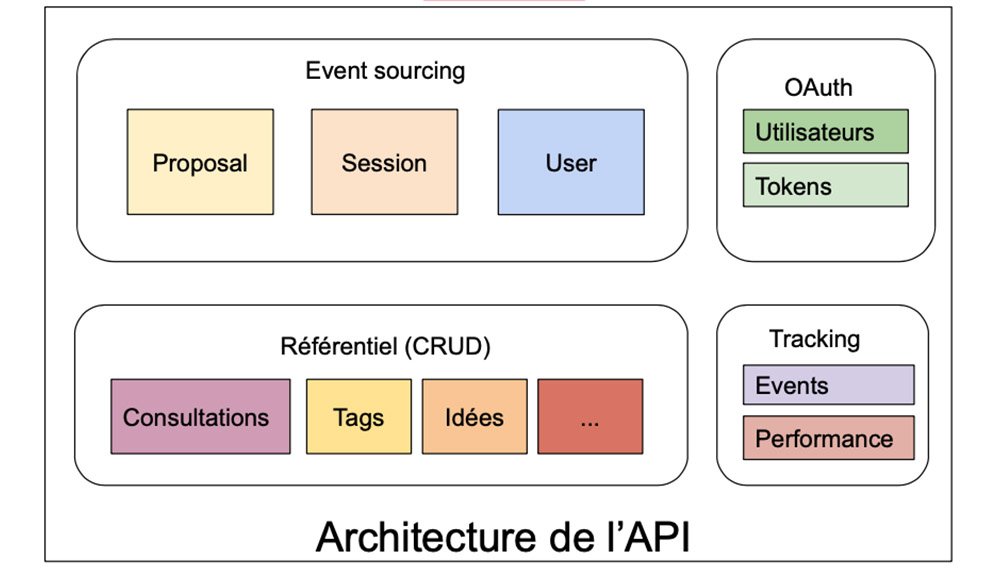
Retour sur la partie applicative
Pourquoi Akka ?
- Performances : event sourcing avec des entités en mémoire
- Montée en charge : les entités sont distribuées
- Data-Native : tout message modifiant l’état donne lieu à un événement utilisable lors des analyses de données
Les acteurs Akka
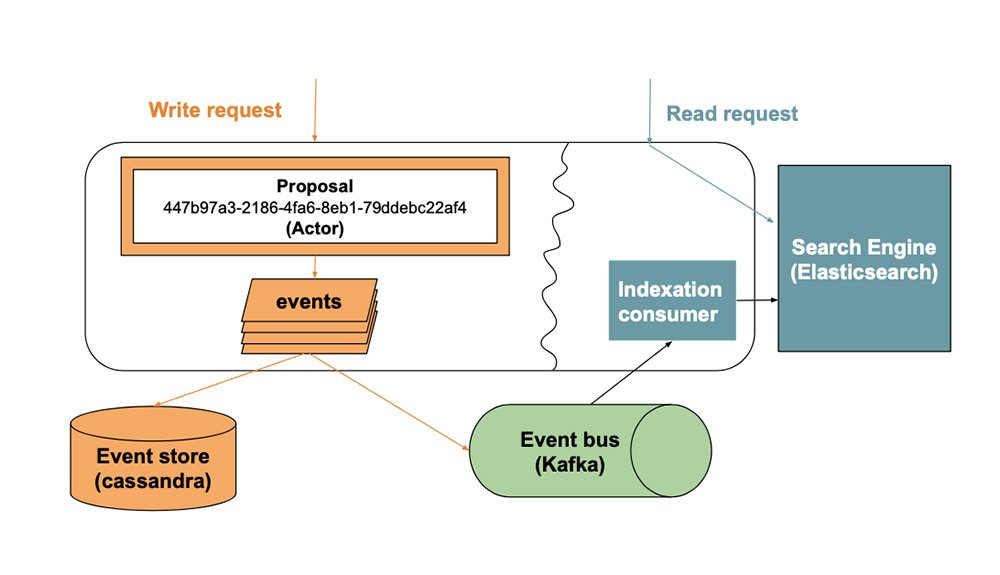
CQRS, Event sourcing
Sharding
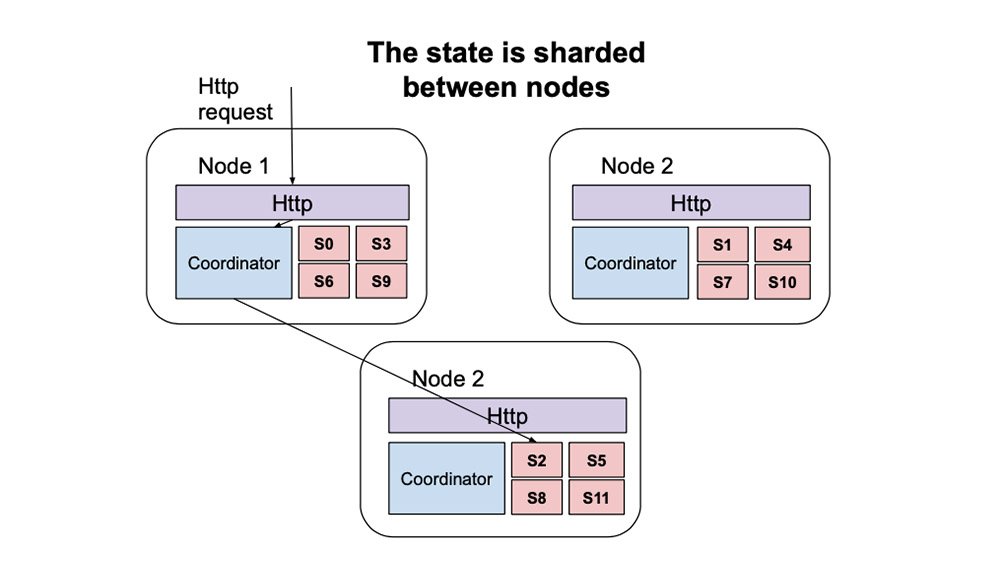
Architecture applicative
Gestion des acteurs

Définir son protocol

Gestion des acteurs V2

Façade d’acteurs

Tout est asynchrone
- La communication avec les acteurs se fait souvent par des futures
- De manière générale, il faut éviter que le code bloque
- Une grande partie des outils scala utilisent des futures
Les pour et les contre des futures

Akka-stream à la rescousse
Des flows qui vont à la vitesse des éléments les plus lents pour éviter de mettre le système en péril. Un vrai contrôle du parallélisme, peu importe dans quel pool de thread les traitements s’exécutent ensuite, notamment avec mapAsync. Attention cependant avec les graphs qui sont souvent compliqués à relire, peuvent donner des maux de tête et peuvent avoir des soucis de terminaison de flow.Initialisation de l’application
 La classe StartShard est définie pour la méthode d’extraction du shard mais pas pour l’extraction de l’identifiant d’entité
La classe StartShard est définie pour la méthode d’extraction du shard mais pas pour l’extraction de l’identifiant d’entité
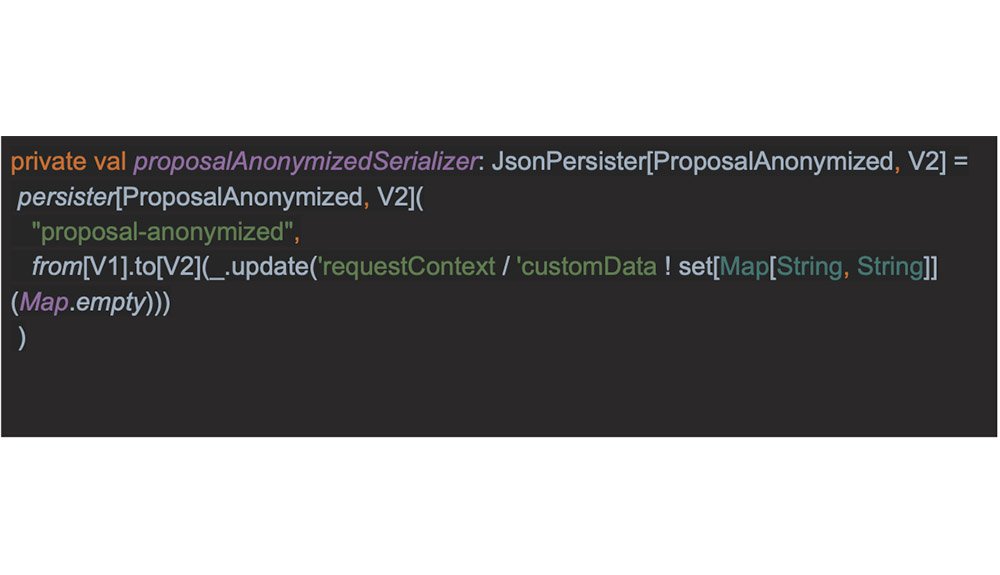
Évolution des événements.
Deux philosophies :- Les événements sont immuables, l’application doit être capable de relire les vieilles versions
- Il est plus simple de faire évoluer les événements en base plutôt que de supporter les versions
Évolution de version avec stamina
Retours sur la partie opérationnelle
Déploiement, mises à jour et haute disponibilité
- Déployer son cluster Akka
- Stratégies de mise à jour
- Upscaling et downscaling
- Reprise sur erreur
Docker swarm
Gestionnaire de conteneurs dockers, lance des service, les monte en charge et s’assure qu’il y a bien le bon nombre de conteneurs pour le service. Isolation réseau très forte. Un peu comme kubernetes mais en beaucoup plus simple.Formation du cluster — V1
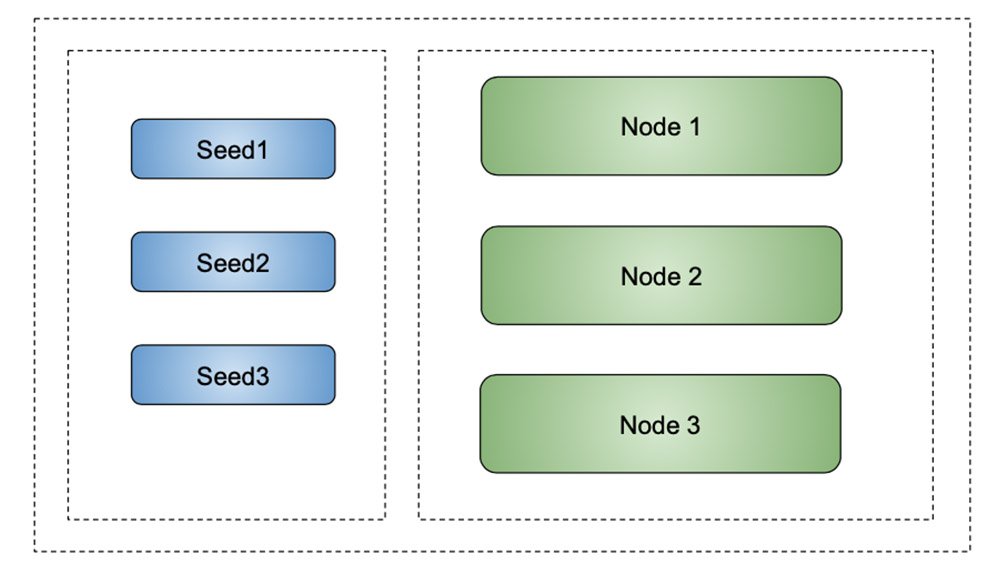
Formation du cluster — V2
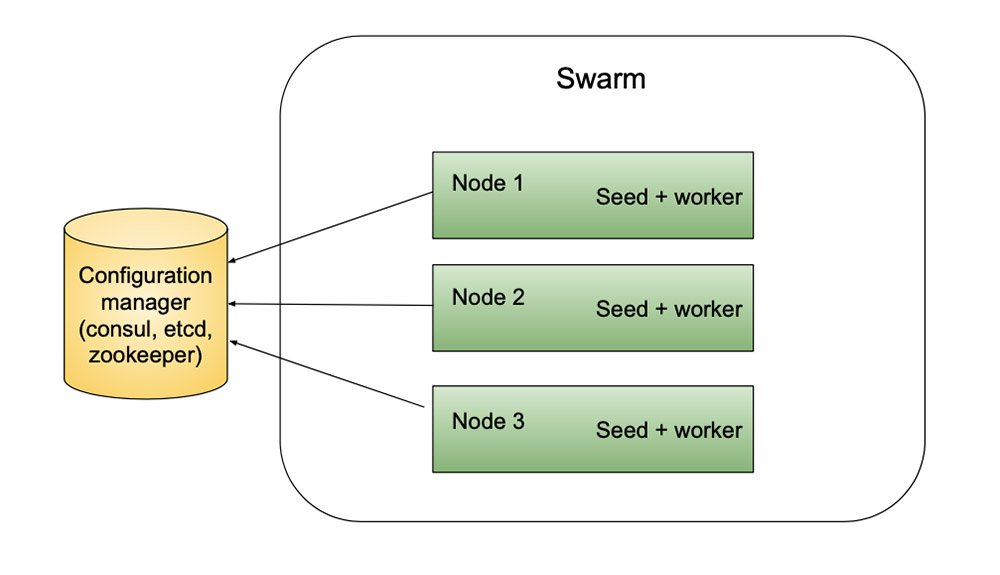
Les bibliothèques pour former le cluster
Constructr- Deprecated pour akka-management
- Garde une vue consolidée du cluster dans un gestionnaire de configuration
- Spécialisé dans la création de clusters dans des environnements cloud
- Permet notamment l’utilisation de DNS pour trouver les noeuds
- Montée et descente en charge
- Split brain
- Gestion des noeuds qui tombent
Montée / descente en charge
Montée Dès lors que la formation du cluster est automatisée, la montée en charge consiste à ajouter des noeuds et akka gère tout seul le reste. Descente Dès lors que le délai les noeuds ont le temps de s’éteindre normalement, tout se passe bien.Split Brain
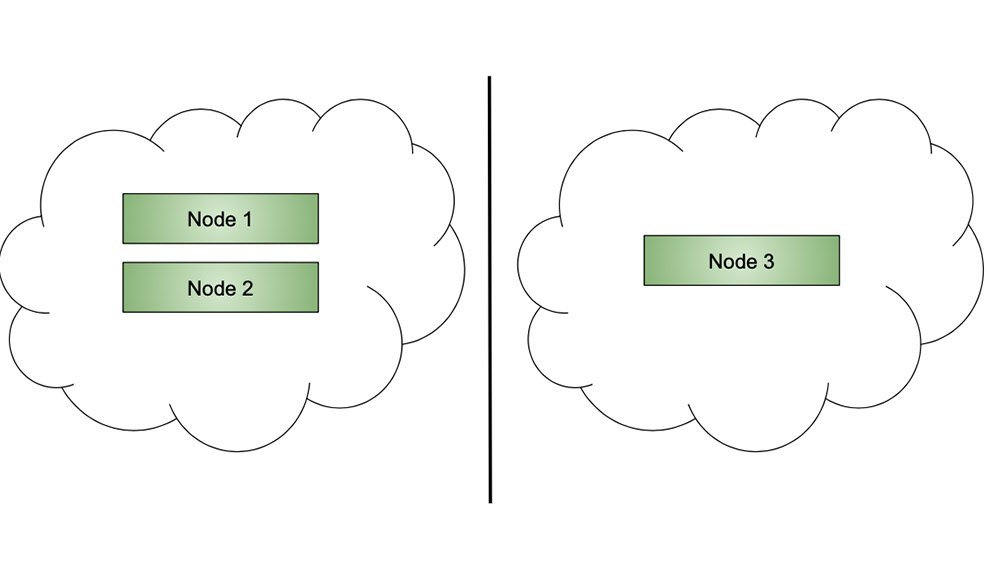
Tolérance à la panne / split brain
- Par défaut akka ne down pas les noeuds
- Nous utilisons constructr et sa vue consolidée pour faire des down sur des noeuds n’arrivant plus à faire des heartbeat sur l’outil de configuration
- Dès lors que des noeuds n’arrivent plus à communiquer avec le gestionnaire de configuration pendant un temps suffisamment long, ils sont retirés du cluster et un down est effectué sur eux
- La décision est reportée sur le gestionnaire de configuration
Exemple de configuration
Nous avons deux paramètres avec une incidence sur le temps de détection qu’un noeud tombe :- refresh-interval : interval de rafraîchissement du heartbeat
- ttl-factor : nombre de heartbeats manqués avant d’être retiré du cluster
Monitoring
Nous utilisons Kamon avec prometheus, et grafana pour de la visualisation
Simplicité d’ajout de métriques

Tenue en charge
Des tests de charge en continu avec Gatling Une très bonne efficacité performance / infrastructure akka-http très respectueux des applications et de l’infrastructure : même après un gros test de charge, l’appli est tout de suite prête pour le suivant, sans devoir tout redémarrer
Points d’attention
- Il faut bien gérer ses pools de thread
- Les ralentissements réseau peuvent faire mal : dans un système distribué, rien n’est pire qu’un membre du cluster qui fonctionne lentement ou par alternance
- Attention à la sérialisation dans l’event store, idéalement, ajouter des TU de sérialisation avec les différentes versions sérialisées
- Les appels d’acteurs peuvent être distants de manière trop transparente
Conclusion
- Akka tient ses promesses et gagne à être utilisé
- Certains use case seront plus simples en dehors d’akka
- Malgré le discours de toolkit et non de framework, il y a clairement ce qui est exécuté en mode acteur et ce qui ne l’est pas
- akka-typed promet de répondre à certaines problématiques de la partie acteur normale, notamment le Any => Unit
- Il y a une réflexion autour de l’utilisation des futures