
Voici un récap’ des présentations faites par Clément Denis (CTO AODocs) et Jean-Marc Leoni (CTO Akur8) lors de notre dernier Mobitalks Java !
Clément Denis : Serverless Java with Google Cloud Platform.
What serverless really means?
Clément’s motto : Maintaining servers (including virtualized or containerized) is hard. If you can have someone else take care of servers for you, just do it.The levels of abstraction of infrastructure services
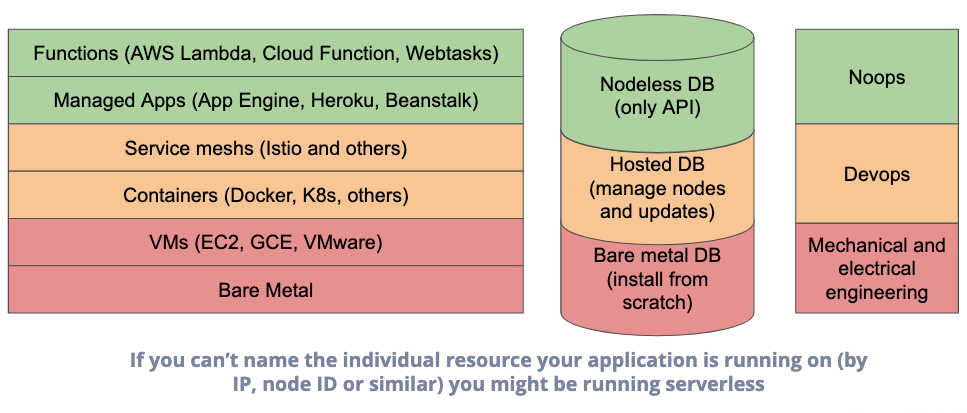
Serverless everywhere, not only the production environment
Developers should develop in the Cloud As instances deploy and start almost instantly, no point in developing locally most of the time Go serverless for EVERYTHING, including dev tools Code: Github, Gitlab, Bitbucket CI: Travis, Gitlab CI, Bitbucket Pipelines Ticketing: Jira Cloud, Gitlab IDE? ⇒ Gitpod But beware of customer data location! You should always be in control of the customer data RGPD is not a joke, always check third-party services TOS If possible, try to colocate everything in the same place
Pros and cons of Serverless
No ops means cheaper, faster go to market A startup going serverless for the launch of its product won’t have to hire a Devops guy / team, and will ship faster Infinite scalability Serverless makes you think in a different way: your app MUST scale horizontally, which is usually a good thing Security and updates are their problem, not yours Google, Amazon or Microsoft will always know about critical security flaws before you, sorry! Focus on what’s important: your application Your application is what matters, not the underlying infrastructure Performance scales really well, but so does cost Serverless means trading performance bottlenecks with cost management Harder to design properly Your app must scale horizontally, so forget about big batch jobs in a background thread Less control of runtime environment You’re not in control of everything, so you might have to wait for this wonderful new Java version Vendor lock-in Your application will be harder to move to another Cloud providerWhat is AODocs running on?
A Document Management system for Google Drive
5 million users Can be installed on a G Suite domain Integrates very well with the G Suite ecosystem A Chrome Extension for Google Drive Hundreds of millions of files managed in Google Drive And growing fast! To the billion and more …
A Document Management system for Google Drive
A single multitenant SaaS app for thousand of customers We do “real” cloud: the application was designed from the beginning to run in a Cloud environment Tens of millions of inbound and outbound requests per day Scales almost instantly from a few to a few hundreds instances, depending on traffic Mostly Java 8 (exploring Java 11 and Kotlin) Main app in Java 8, deploying Java 11 and Kotlin microservices Servlet 3.1 and App Engine SDK with a few frameworks ORM ⇒ Objectify (annotation based, Datastore specific) REST API ⇒ Cloud Endpoints Framework Google APIs ⇒ google-api-services-* and google-cloud-* Utils ⇒ Guava, Lombok, Jackson, etc.
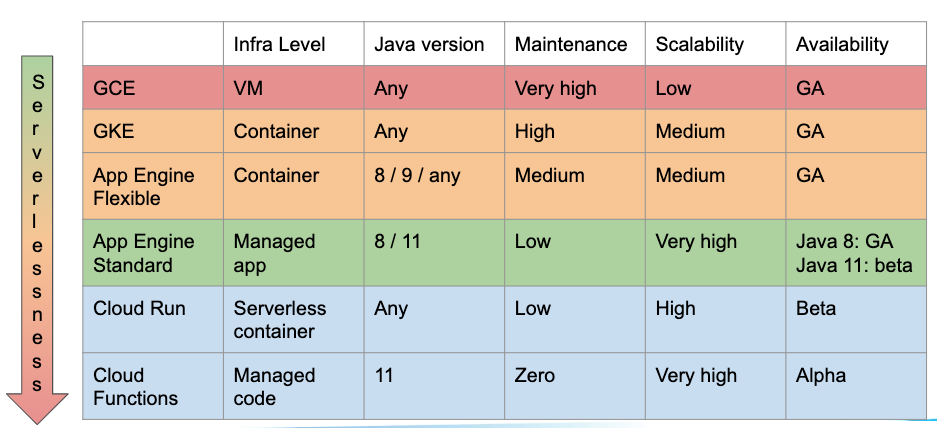
Java on GCP: what are my options?
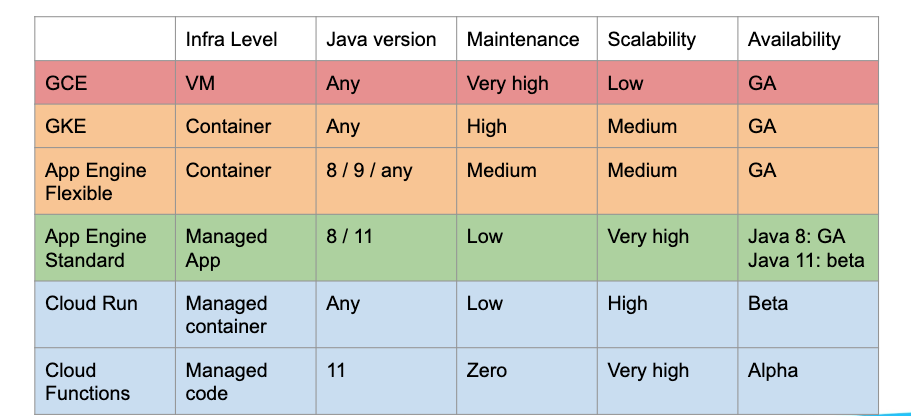
App Engine: the one-stop shop for serverless
Services and versions Multiple services with multiple versions running simultaneously One URL for each version, routing based on host or path Zero downtime when switching between versions Flexible serving infrastructure Custom domains with HTTPS (Let’s Encrypt or provided) Traffic splitting for A/B testing or progressive rollout Datastore NoSQL database Infinitely scalable (really!) Nice Java ORM framework: Objectify Memcache Millisecond-range operations Speeds-up Datastore as a level 2 cache Full-Text Search Simple but very reliable and extremely scalable Zero maintenance ever Tasks and Crons Split your heavy jobs in smaller units of work Schedule recurring operationsApp Engine for Java: comes in two flavors

App Engine for Java: differences between 1st and 2ng generation runtimes

App Engine for Java: differences between 1st and 2ng generation runtimes

Java on GCP: what are my options?
How are we monitoring our Java apps?
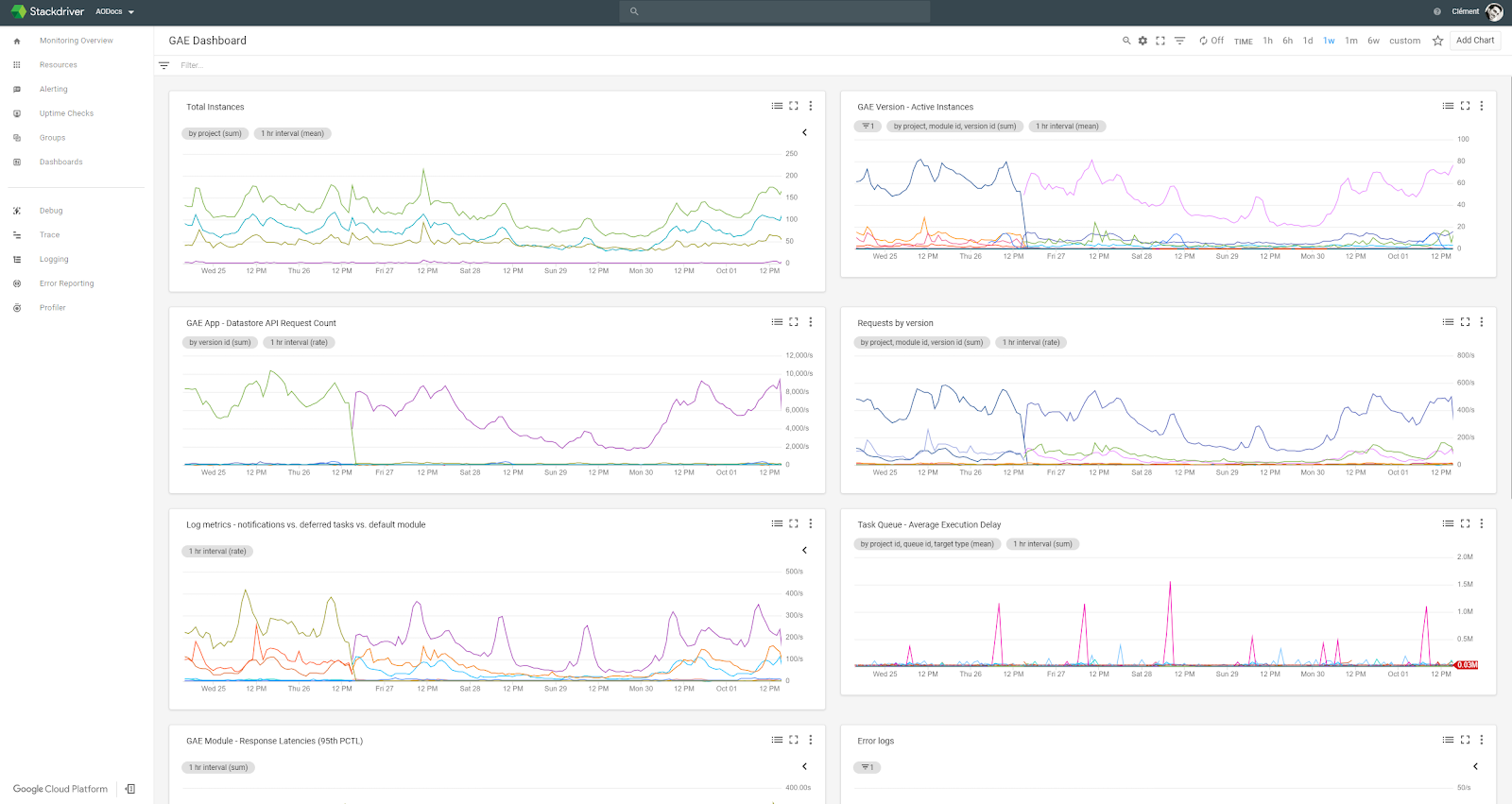
Stackdriver and BigQuery: the perfect couple Stackdriver charts and alerts: forget about ELK!
Stackdriver charts and alerts: forget about ELK!
Stackdriver logs and error reporting
Use your preferred logging abstraction SLF4J, Commons Logging, Lombok, … Just make sure it writes to java.util.logging Store and analyze in BigQuery Logs are only stored for 30 days ... but you can export them in BigQuery forever Analyze long term latency trends Troubleshoot something that happened 6 months ago Let Google tell you what’s wrong Stacktraces are analyzed automatically and grouped Helped us a LOT to spot subtle mistakes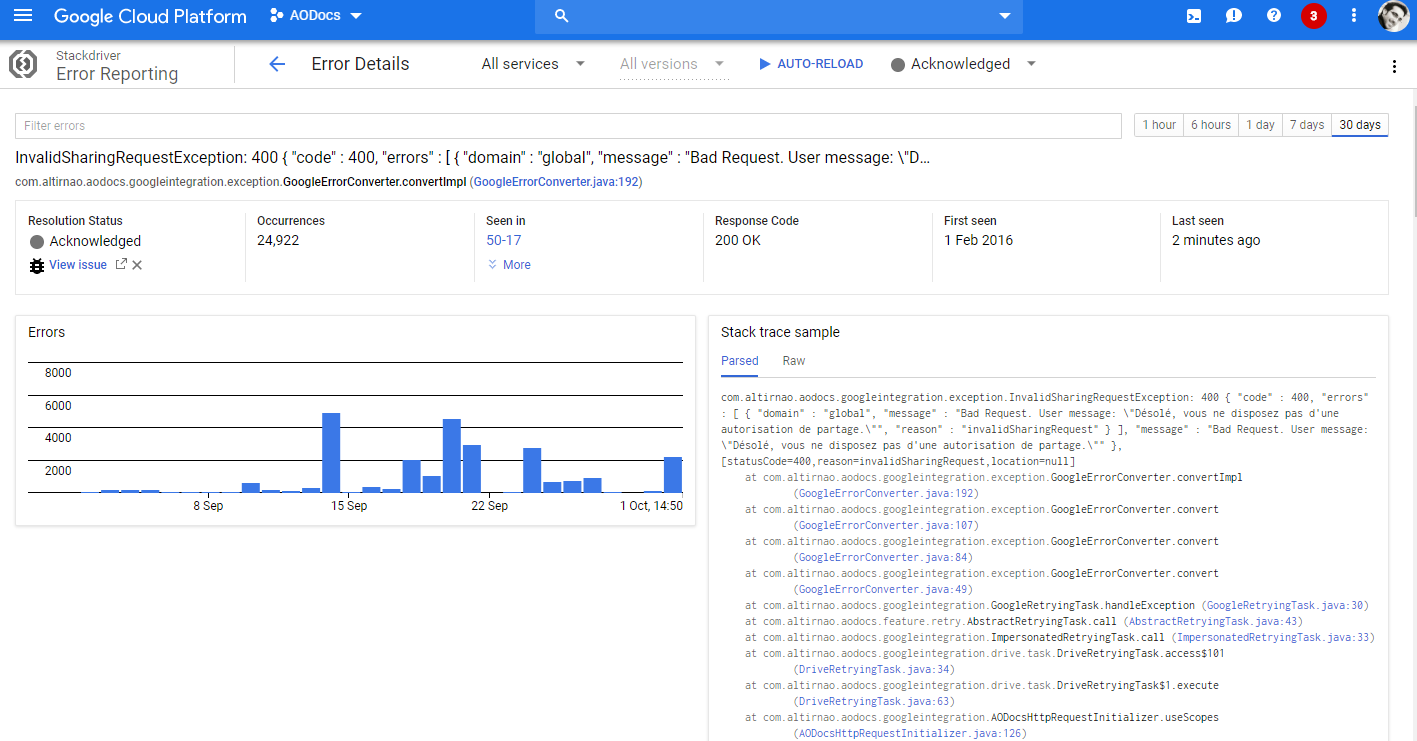
Stackdriver Tracing
Analyze latency by request path Easily spot outliers Automatic metrics for App Engine services Detailed tracing comes for free (no code) Add your own spans with some code Based on OpenCensus Compare latency distribution between versions Automatic reports or create your own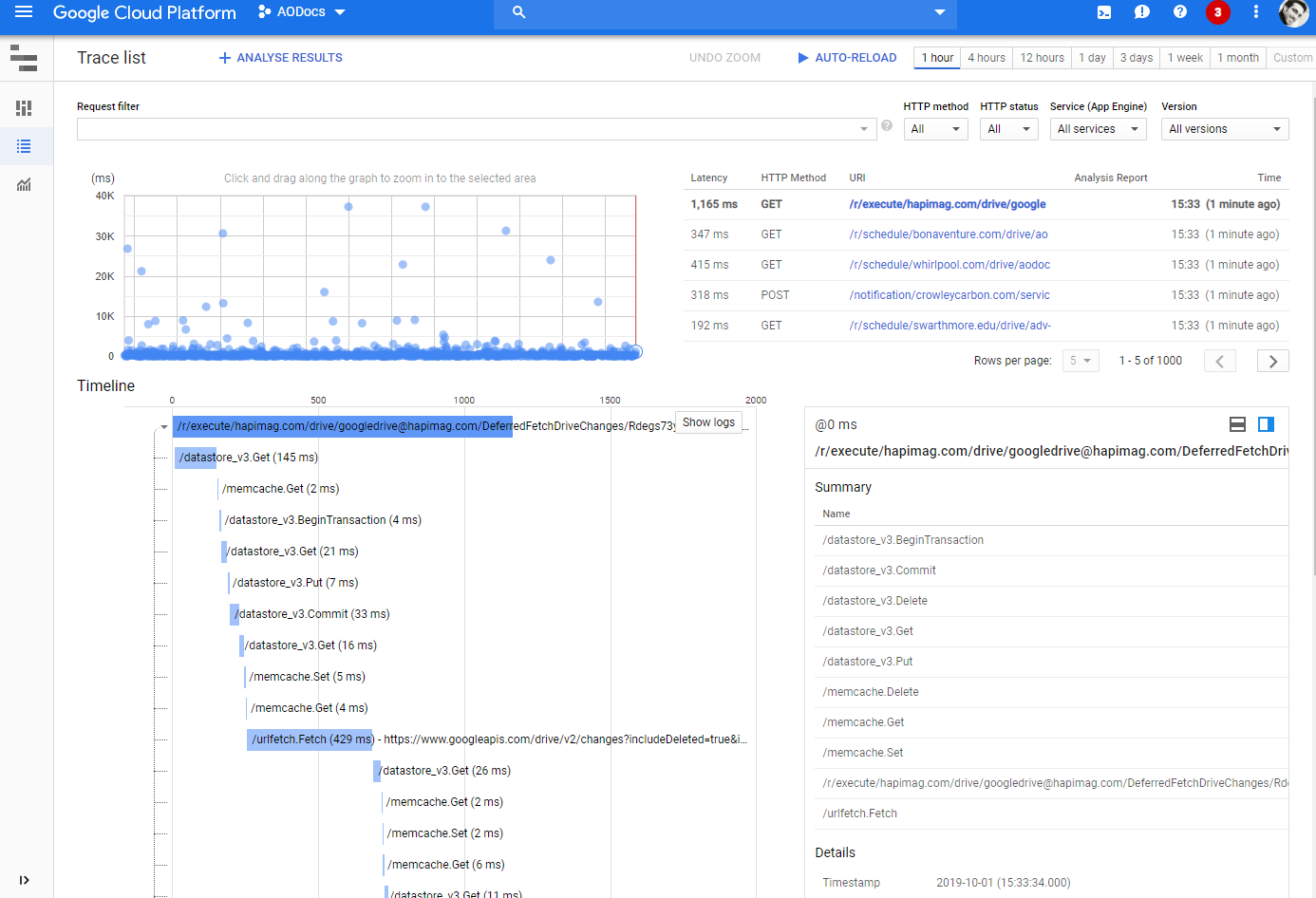
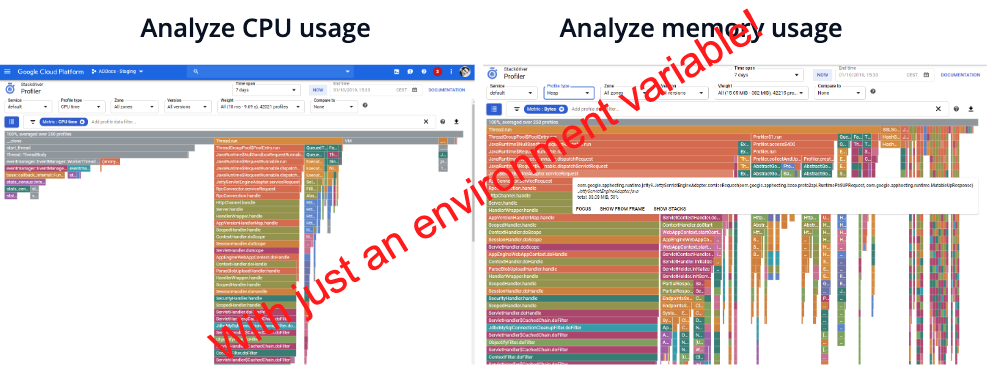
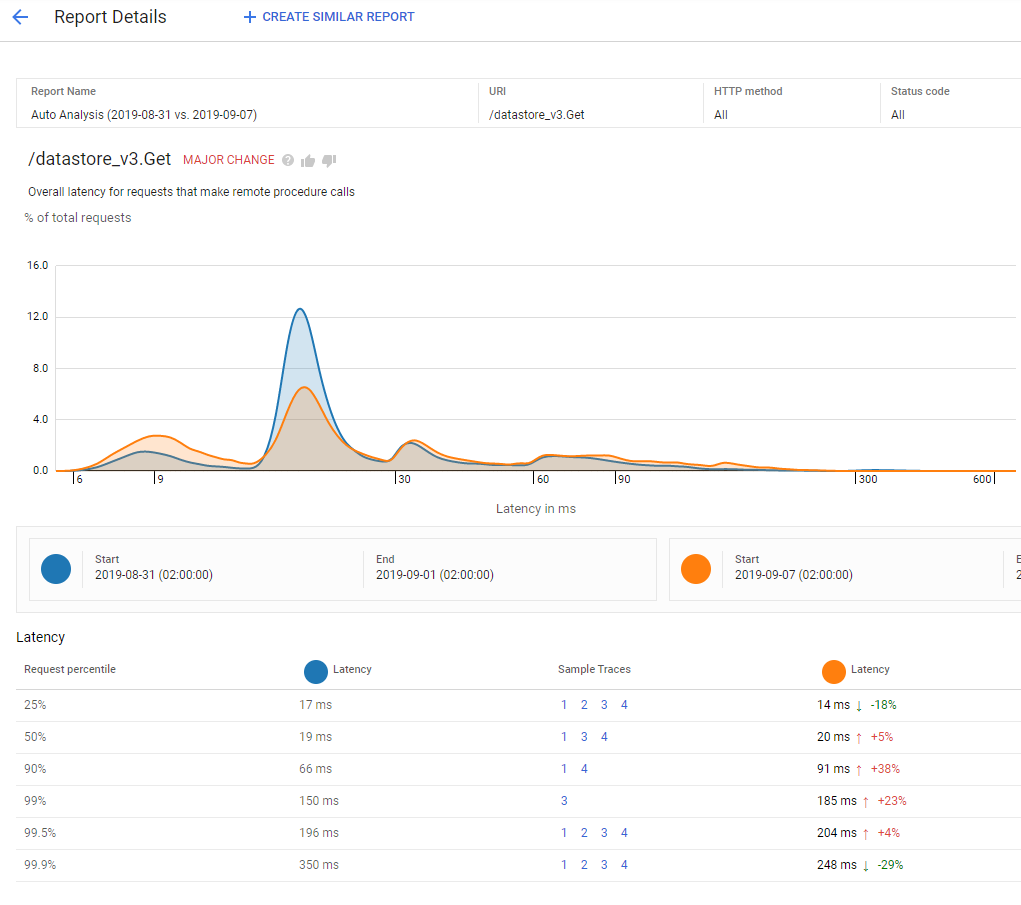 Stackdriver Profiling
Stackdriver Profiling
Stackdriver Debugger
Add “breakpoint” in your production code From your IDE (supports IntelliJ) or from a web editor No perf penalty, actually dumps the variable state Add additional logs at specific code points Never again: “If I just had thought about adding some logs …” But let’s be honest: it’s mostly a very nice toy :-) Only helped us a couple of times in the last few years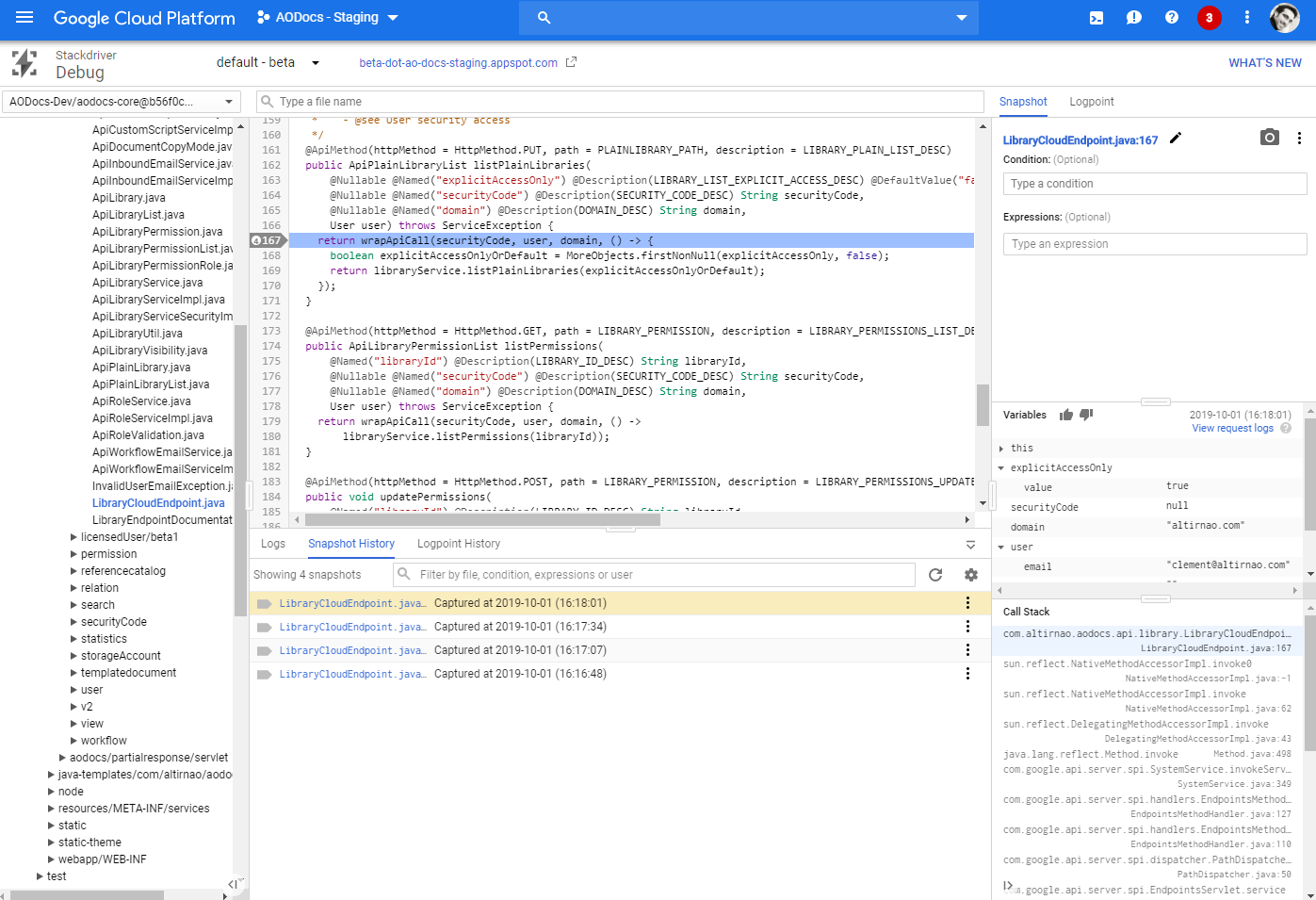 Références :
Martin Fowler on Serverless: https://martinfowler.com/articles/serverless.html
GCP Serverless solutions: https://cloud.google.com/serverless/
App Engine: https://cloud.google.com/appengine/
Serverless Framework: https://serverless.com/
Références :
Martin Fowler on Serverless: https://martinfowler.com/articles/serverless.html
GCP Serverless solutions: https://cloud.google.com/serverless/
App Engine: https://cloud.google.com/appengine/
Serverless Framework: https://serverless.com/
Jean-Marc Leoni : “serverless” chez AWS avec Spring et AWS batch pour traitement asynchrone long dans l’univers Java.
Le serverless pour le batch processing
On peut le faire avec du FaaS (souvent):- Processing ligne à ligne (feature engineering, data cleaning)
- Données peu volumineuses
- Toutes les données doivent résider en RAM
- On ne peut pas distribuer
AWS Batch
Permet de définir des Job Definitions et de lancer des Jobs Job Definition : une image docker, une ligne de commande et une quantité de CPU/RAM Job : une instance d’un job Definition qui est lancée sur un Compute Environement Queue : un file pour mettre les jobs en attente Compute Environnement : un ensemble de machines qui sont lancéesà la demande et sur lesquelles les jobs s’executent (évolue en nombre de CPU)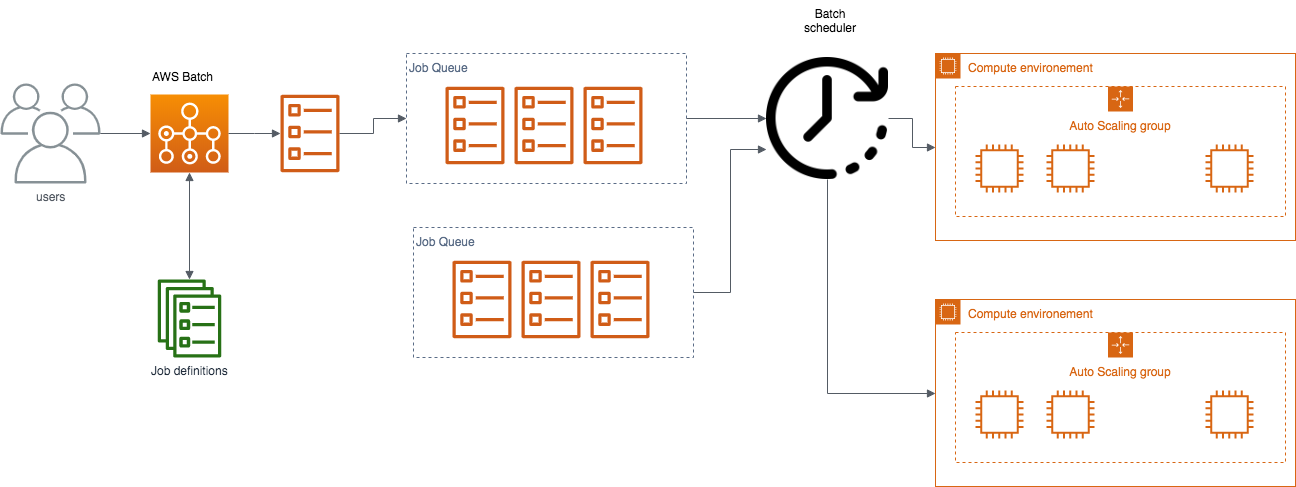
Et spring dans tout ça ?
Spring Batch- Pratique pour définir des pipelines de traitement
- De la connectivié JDBC/JPA
- Facilite l’intégration avec les providers de cloud
- DB managées
- Microservices